
以前Transformerを適当に作って、適当なデータセットで学習させてみてます、という話を書きました。
未だに学習続けているんですが、2週間くらいチミチミ学習させて、今このざまです。
Input: あなたの名前はなんですか?」「私は
Output: おおおおお、おおおおおおおおおお、おおおおおおおおおおおおおおおおおおおおおおおおおお
なんてこったい。
モデルとしてはGPT-2のSmallと同じサイズ(d_model=768 , num_layer=12, num_head=12)です。
データセットは青空文庫のものを使っています。
各文章はByte-Level BPEでトークナイズして、300トークンずつに分割してます。
作り方は間違っていない…はずで、徐々に損失は減っているのは確認しています。
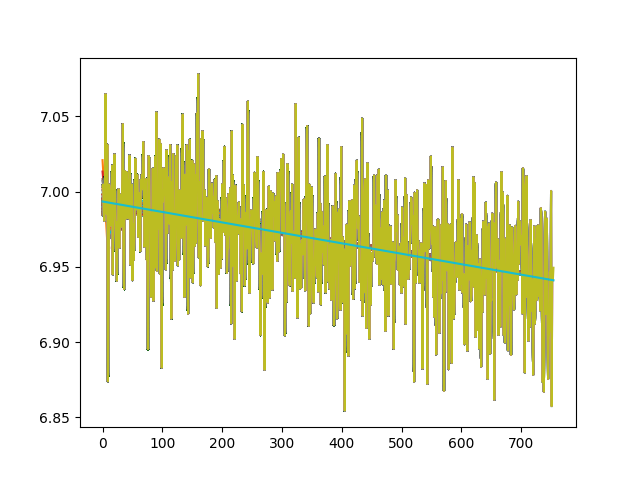
まぁ私の貧弱なGPUで(かつ多分デスクトップにメモリ食われてる)、細々と訓練している程度だと、まぁこんなもんかなという気もしますがね。
ちなみに、先程の出力例は推論モード?的な感じで生成させたものです。「Inputのトークン列から、どんどん続きを作っていこう」モードです。
訓練モード…「答えの文章が与えられていて、どんどん次のトークンを予測する」モードがあるんですが、そちらの入出力は以下の様な感じです。
Input:ちのまま叱咤した。
「…………」
泰軒は無言。ほお髭が風にそよぐ。
「おのれッ! 応答をいたさぬかッ」
言いかけて、軍之助は声を低めた。
「いままた、同志秋穂左馬之介の仇敵……かくごせい!」
そして!
その氷針のような言葉が終わったかと思うと、さアッ! と一層、月輪の円形が開いて、あるいは谷を背に、他は丘にちらばり、残余の者は刃列をそろえてすばやく山道の左右に退路を断った。
とともに! 一刀流正格の中青眼につけた岡崎兵衛、めんどうなりと見たものか、たちまち静陣を離れて真っ向から、
「えいッ」
はらわたをつんざく気合いを走らせて拝み撃ち!――あわれ泰軒先生、不動のごとく血の炎に塗れさった……と思いのほか刹那! 燐光一線縦にほとばしって、ガッ! と兵衛の伸剣を咬み返したのは自源流でいう鯉の滝昇り、激墜の水を瞬転一払するがごとき泰軒の剛刀
Output:、、、、、を。
�お�………」
�はは、、
、、は、、を。、
「�、、��」��、、は��
とは、
はは、、を。
「�、、おははは、が」、、」が�…�、、、��」
と、��� と�はは、、した。、
。、�� と�は
はは、、、
、がを、
、、、、、、
、、、、、、、、。へを、、、を、。
しかし、�� と、ははははは、、、ははは
は、、、
、はが、、、、
「���」
と、は、。、。、、、、、、した、���
�、は、
、が、ををが、、。�…�、�が、�� は�、はは、、�、
、! �、は�はを、�を、、、、、、、。、、を、、
、、、�、、、、、、、、を、を
文字化けが多いのはByte-Level BPEの影響ですね。UTF-8を1バイトずつ語彙として覚えているため、適切な文字にならないと文字化けするということです。
パッと見て、「句読点を連打すればそれなりのスコアが出る」「改行後にカギカッコが出る」「カギカッコは閉じる」程度は学習してそうです。
ちなみに出典は「丹下左膳 乾雲坤竜の巻」林不忘 のようです。序盤だけ読んでみましたが面白そうです。後で続きを読もうかな。https://www.aozora.gr.jp/cards/000290/files/24376_19396.html

コメント